from setup import ___
from siuba import *
from plotnine import *
from music_top200 import music_top200, track_featuresGroup by
Click here to open the slides full screen.
Exercise 1:
Modify the code below so it calculates max popularity and average danceability for each artist.
artists = (track_features
>> summarize(
max_popularity = _.popularity.max(),
avg_danceability = _.danceability.mean()
)
)
artists| max_popularity | avg_danceability | |
|---|---|---|
| 0 | 99 | 0.677937 |
1 rows × 2 columns
Make a scatterplot of the data.
Show solution
artists = (track_features
>> group_by(_.artist)
>> summarize(
max_popularity = _.popularity.max(),
avg_danceability = _.danceability.mean()
)
)
print(artists)
(artists
>> ggplot(aes("max_popularity", "avg_danceability"))
+ geom_point()
) artist max_popularity avg_danceability
0 #LikeMe Cast 44 0.413
1 #TocoParaVos 42 0.815
2 $NOT 43 0.847
... ... ... ...
7190 黃莉 0 0.544
7191 黃齡 37 0.563
7192 NaN 36 0.245
[7193 rows x 3 columns]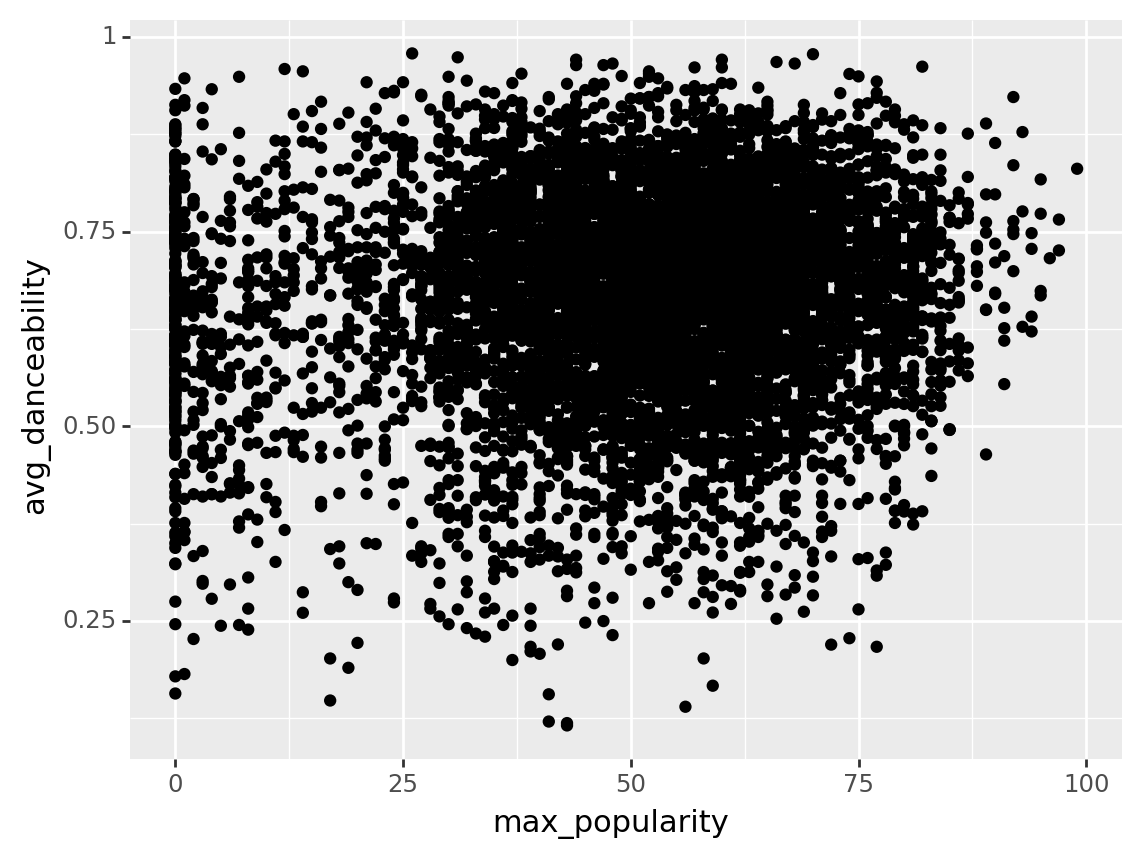
In the plot above, what strange thing is going on with the distribution of max popularity?
possible answer
There are many artists with a max popularity of 0!
Exercise 2:
In the last exercise of the facets chapter, you examined track features for three artists.
# This code keeps the 3 artists listed ----
artists_to_keep = ["Billie Eilish", "ITZY", "Roddy Ricch"]
some_artists = (
track_features
>> filter(_.artist.isin(artists_to_keep))
)
#uncomment line below to see data
#some_artistsWe used a plot and intuition to judge who tended to have highest energy and valence tracks.
# This code plots the data ----
(some_artists
>> ggplot(aes("energy", "valence", color = "artist"))
+ geom_point()
+ facet_wrap("~artist", nrow = 1)
+ labs(title = "Song features across 3 artists")
)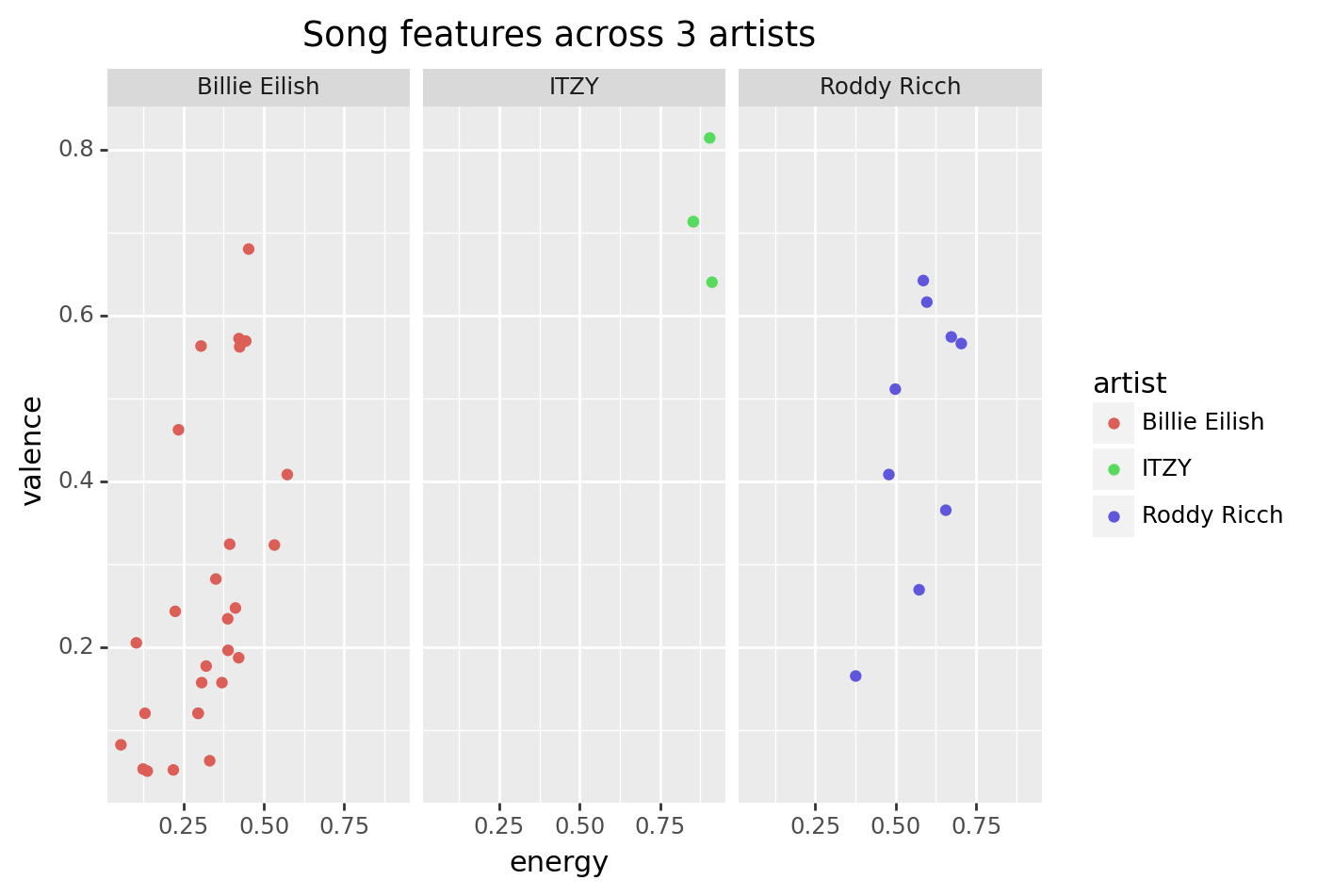
Now you should be able to answer the question more directly!
Use a grouped summarize to calculate the mean energy and valence for each artist.
# summarizing mean energy and valence for each artist
Show solution
# This code plots the data ----
(some_artists
>> group_by(_.artist)
>> summarize(avg_energy = _.energy.mean(), avg_valence = _.valence.mean())
)| artist | avg_energy | avg_valence | |
|---|---|---|---|
| 0 | Billie Eilish | 0.321004 | 0.266948 |
| 1 | ITZY | 0.880250 | 0.720000 |
| 2 | Roddy Ricch | 0.571444 | 0.457333 |
3 rows × 3 columns
Q: In this data, which artist has the lowest average energy, and what is its value?
answer
Billie Eilish, 0.321004Q: What about for lowest average valence?